The past few days have been so exciting, following the giant 1 billion row challenge! . The challenge was created by Gunnar Morling and I decided to go through a few solutions that I found really interesting.
Each solution will have two timing results: one for the Hetzner AX161 (32-core AMD EPYC™ 7502P, 128 GB RAM) which was the dedicated server for evaluation for the challenge, and another for my experimental local runs on an M2 MacBook Air (8-core, 8GB RAM).
Dataset and Task
The dataset consists of 1 billion rows, with each row containing a city name and the temperature, recorded in a file named 'measurements.txt.' The size of the file is approximately 13.8 GB.
The task is to find minimum, maximum and average value per city sorted alphabetically using optimized code. (see image)
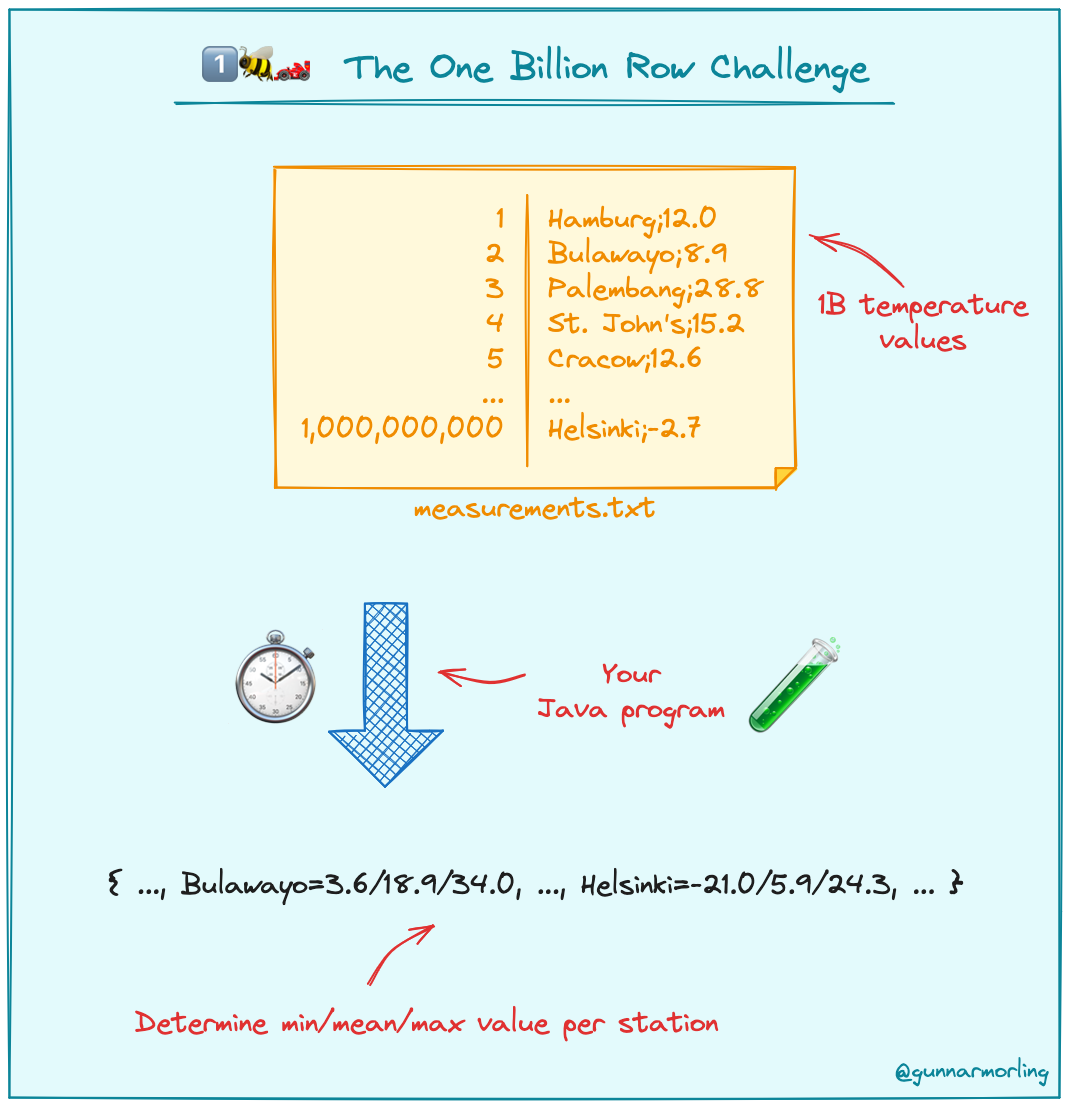 The Dataset, task and required output
The Dataset, task and required output
Pretty easy task, huh? Even a freshman can write code to find those values. But here's where things get interesting: you have to optimize your code to make the calculations extremely fast. As you've seen in the video snippet, the time taken by a few solutions is even faster than the time it takes me to write 'one billion' on a whiteboard.
 Fastest Solution
Fastest Solution
I have tried to understand and explain a few solutions in Java, Python, and C++ in this blog post. The GitHub repository is a goldmine for people interested in parallel processing, threading, SIMD operations, and, in general, software engineering. A few solutions posted are very specific to the given text file, while most of them are general and can be applied to any dataset. So, without further ado, let's dive into the solutions.
1. Java Solutions
1.1 Baseline Solution
The baseline solution was posted by the author himself and it's quite easy to understand. This solution utilizes the Record class and Collectors class to aggregate and perform reduction operations on the data. Here's the core idea
 Baseline solution
Baseline solution
The heart of this solution is the collector. The collector has four components supplier, accumulator, combiner and finisher. The main purpose of the collector is to collect a stream of data from each row, calculate the required values, combine results from different threads, and finally convert the accumulation into the desired output format.
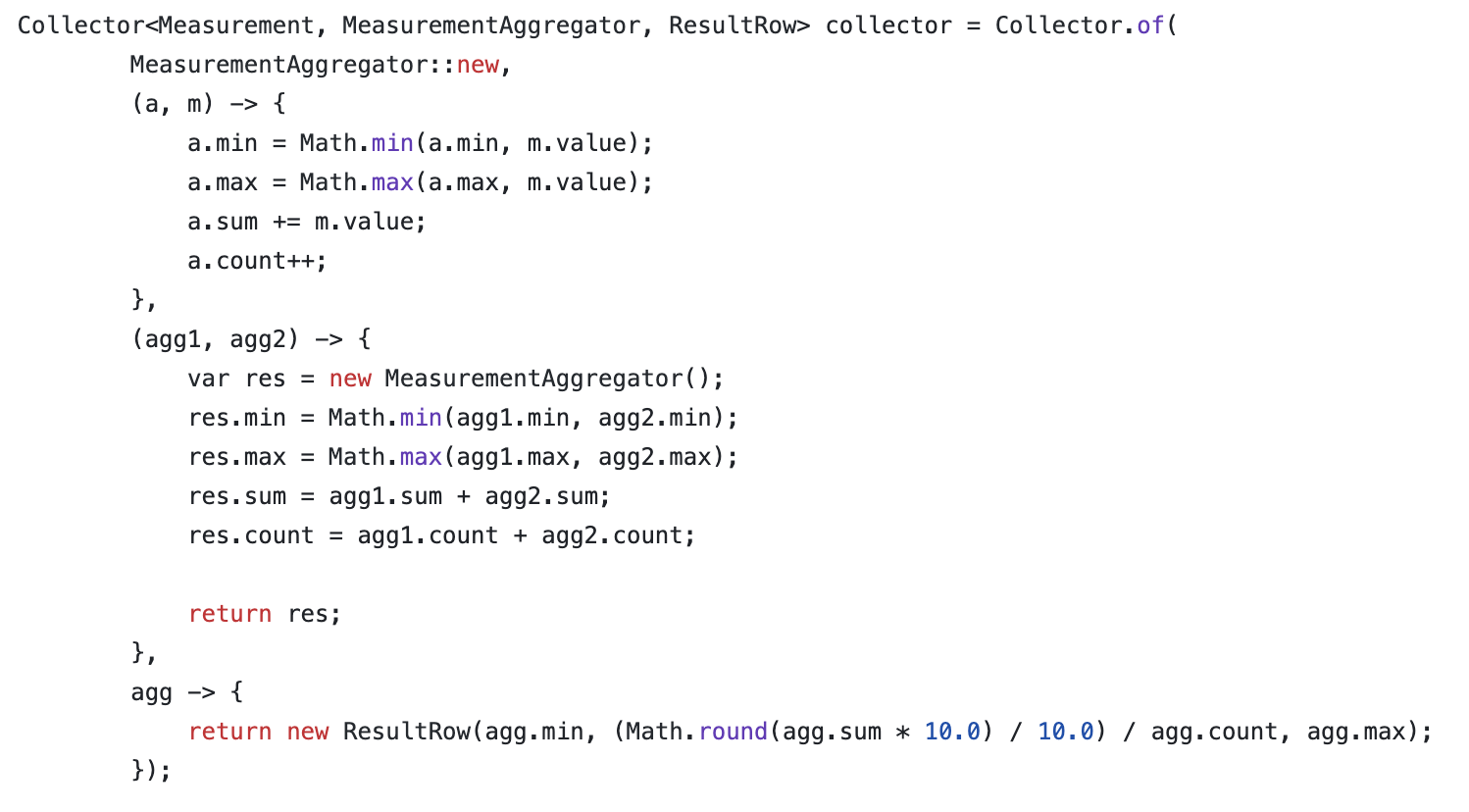 Collector class
Collector class
The time taken by the base solution on Dedicated server(Hetzner AX161) and locally (M2 Air) are
- Hetzner AX161 - 4min 49 sec
- M2 Air - 5 min 23 sec
1.2 Baseline Solution (optimized)
The above code ran on a single core. With just two line change we can run the code on mutiple cores and optimize the performance. I found this useful trick in this blog
 Java parallel cores
Java parallel cores
Time taken
- Hetzner AX161 - not available
- M2 Air - 2 min 57 sec
1.3 Reading file in Chunks
Another Java solution I found interesting was given by Vlad. In this solution the author read file in chunks, which is particularly useful for processing large files. The solution has three major classes ChunkReader,RowReader and Measurement class.
The ChunkReader Class read the file using chunck size of 1MB as ByteBuffer object. Then, the RowReader class takes these chunks as input and split it to individual rows containing City names and temperatures. Finally using the measurement class the operations on these rows are performed and results are aggregated in a concurrent map. Here's the snippet of the main method
 Chunking Solution
Chunking Solution
The beauty of this code is that it excels in handling large files by cleverly reading them in manageable chunks, preventing memory overload. It employs parallel processing, speeding up data handling and analysis.
Time taken
- Hetzner AX161 - 12.5 sec
- M2 Air - 28 sec
2. Python Solutions
2.1 Polars and Dask library
Now, coming to my favorite language - why is it my favorite? Because there's a library defined for practically everything. In this case, we got lucky, as there are two such libraries that can parallelize the data with just a few lines of code. Here's the snippet of complete solution using Polars given by Taufan
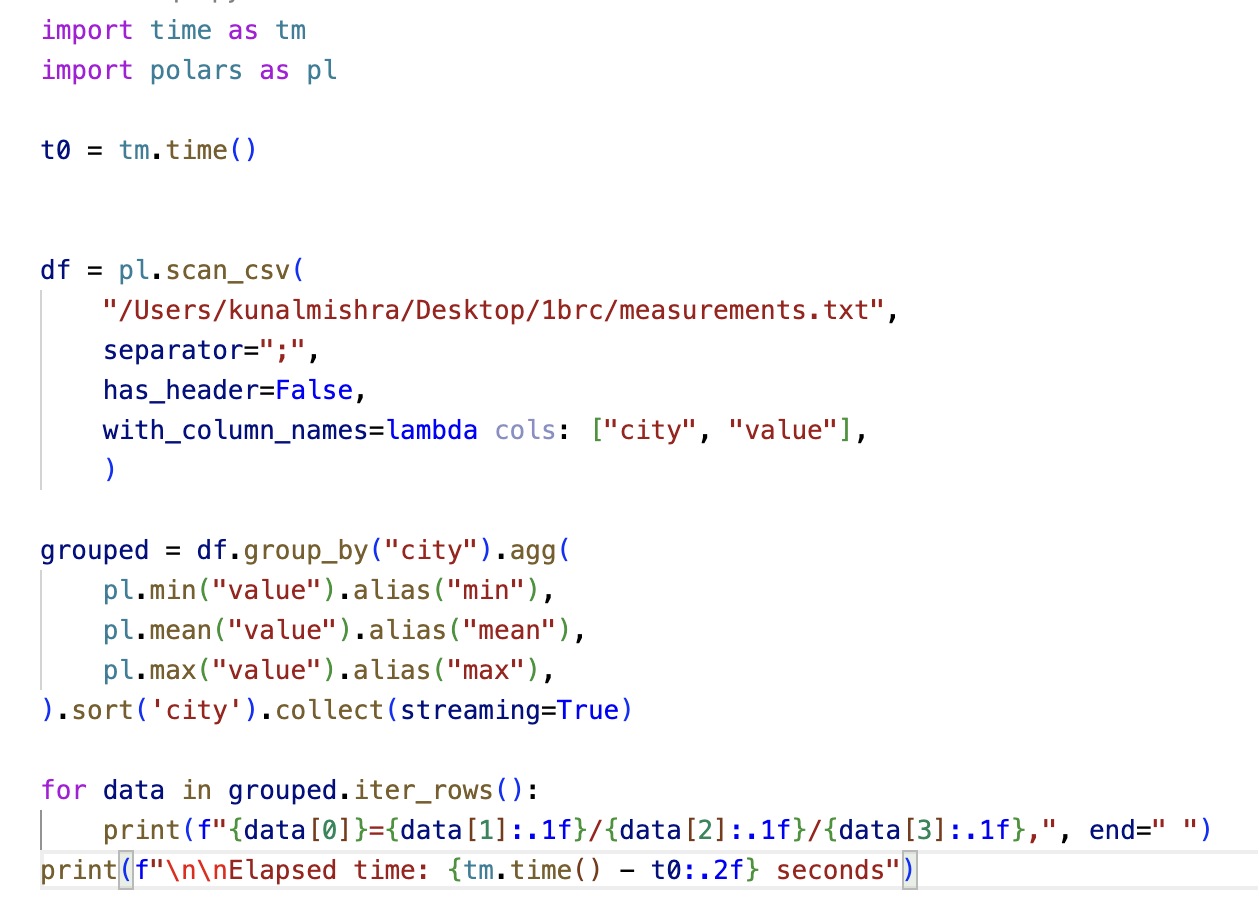 Python Polars Library Solution
Python Polars Library Solution
Yes, that's it. That's the complete code. The code is very easy to understand. In the first step we create a dataframe from measurements.txt and then just run a dataframe operation to aggregate and sort the results. All the parallelization is done internally without any additional configuration. We can do the similar thing using Dask library, here's the Dask solution given by Sara
Time taken
- Hetzner AX161 - 9.19 sec
- M2 Air - 43.6 sec
2.2 Multiprocessing and chunking
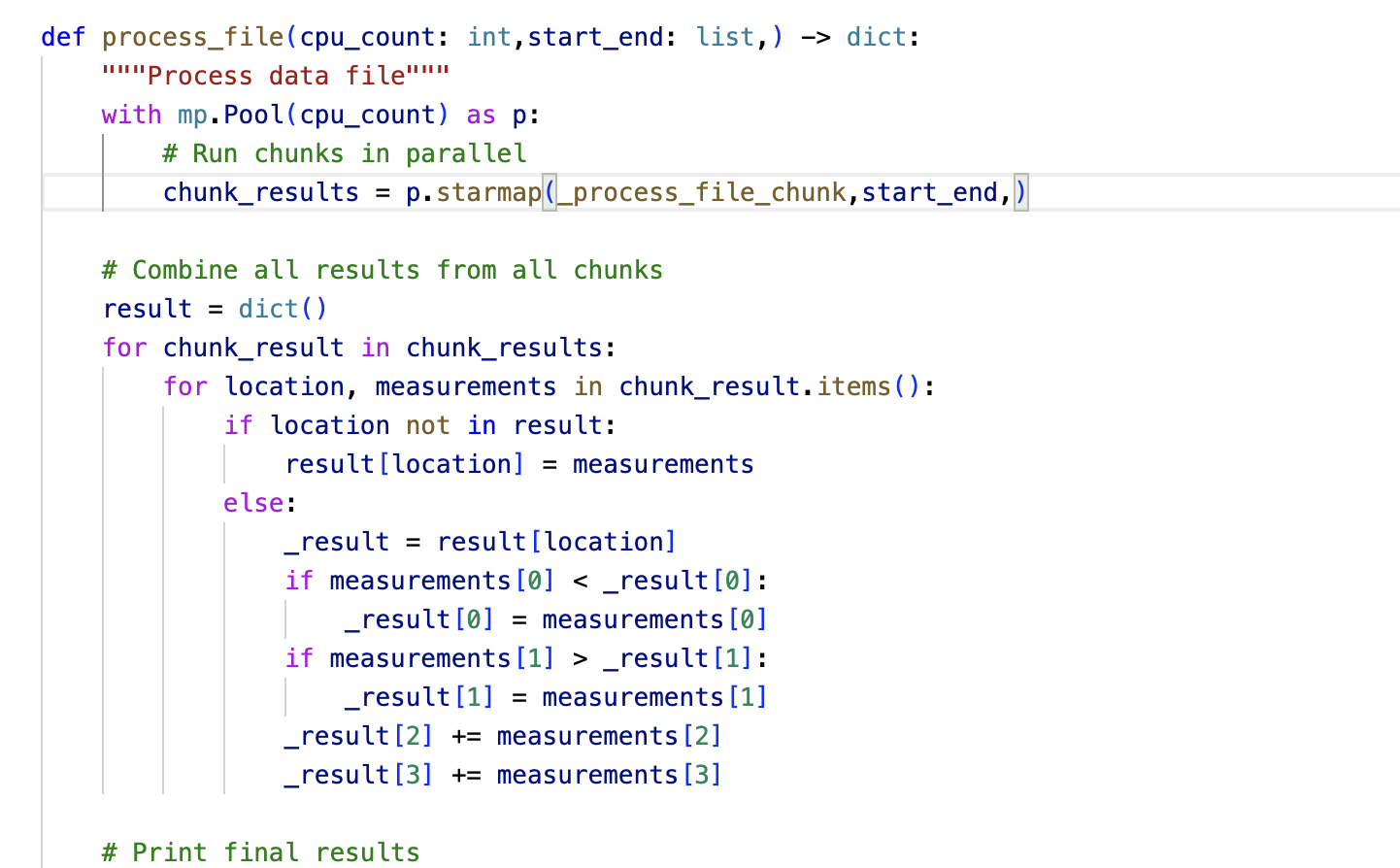
There has to be some code where you can tune the parameters and understand the implementation details in Python. I found one such solution from Italo Nesi. In Python concurrency and parallel programming is implmented using Multiprocessing library. The solution has methods such as get_file_chunks, process_file and process_chunk.
In get_file_chunks method we define the path of file , find out number of logical cores using cpu_count(),and then find the chunk size which is defined as total_file_size/number_of_cores. The chunk size came out to be 1.7 GB. Here's the snippet
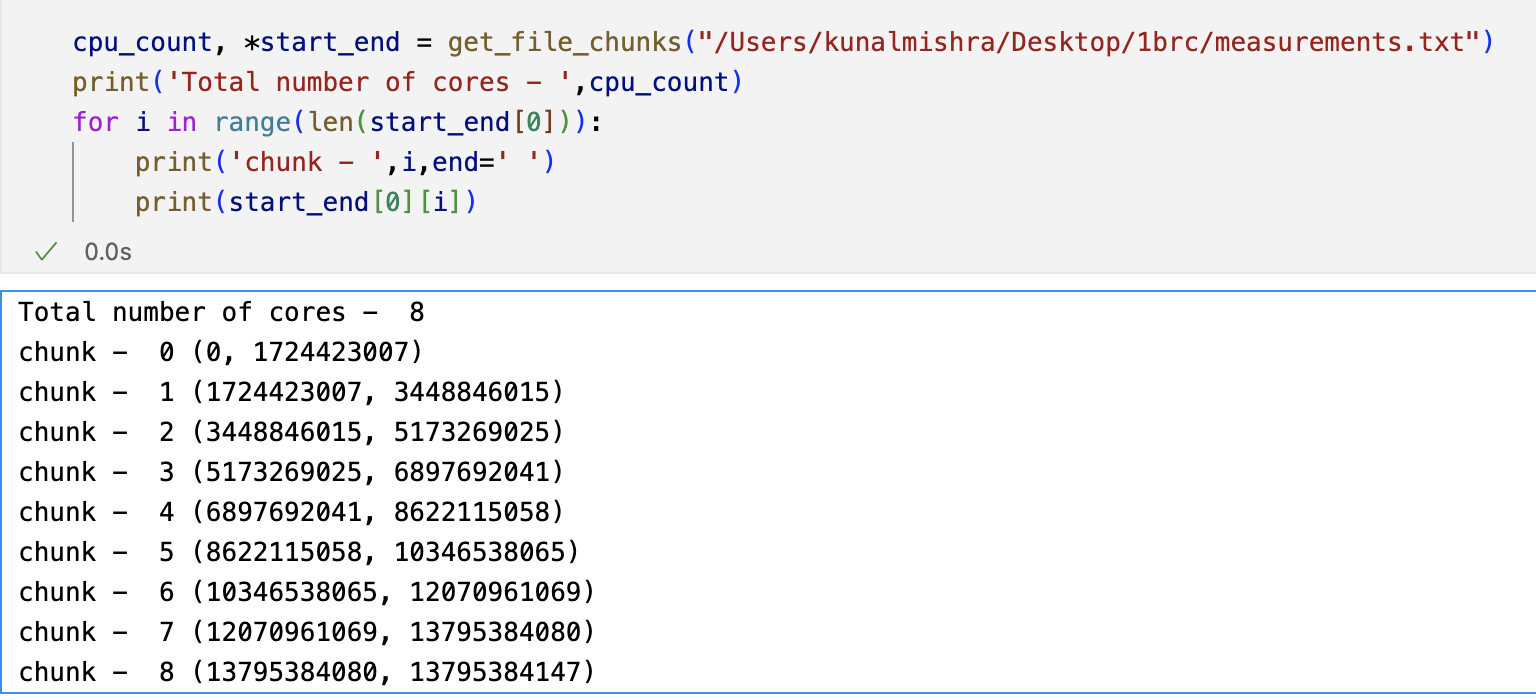 Python Chunking
Python Chunking
Now we pass the processed chuncks to process_chuck method which will read each chunk line by line parallely and find the min, max and average of values. Finally we combine results from all the chunks and then sort them according to the given output.
 Python Chunking
Python Chunking
Time taken
- Hetzner AX161 - 45 sec
- M2 Air - 1 min 40 sec
3. C/C++ Solutions
There's a reason why you should save dessert for last. The OG language, unmatched in its capabilities when it comes to optimization and memory efficiency. The time taken to perform the given tasks on 1 billion rows is merely 0.28 seconds. Just for the time reference , blinking an eye takes about 0.3 seconds.
 Blinking
Blinking
I was blown away when I saw the solution. I am still in process to understand it completely. However the author has used the following main ideas to make it extremely fast solution
- Unsigned int overflow hashing: cheapest hash method possible.
- SIMD to find multiple separator ';' and loop through them.
- SIMD hashing.
- SIMD for string comparison in hash table probing.
- ILP trick (each thread process 2 different lines at a time).
- Parse number as int instead of float.
- Use mmap for fast file reading.
- Use multithreading for both parsing the file, and aggregating the data.
Time taken
- Hetzner AX161 - 0.28 sec
Conclusion and Learnings
In this blog, we have discussed only a few solutions. According to the competition's rules, the solution had to be implemented in Java, and the leaderboard features only Java solutions. Most of these solutions delve deeply into threading and concurrency. However, there are also solutions in Go, SQL, Snowflake, Rust, Erlang, Fortran, and even Cobol. You can find all the discussions here.
I want to reiterate that the challenge is a goldmine for developers of all levels. Whether you're a Data Engineer or a Senior Software Developer, it's crucial to find ways to load and preprocess data as quickly as possible.
Thank you for reading. Feel free to drop an email or ping me on LinkedIn if you want to discuss new solutions or have any reviews about the blog.